i4Q Guidelines for Building Data Repositories for Industry 4.0#
1. Introduction#
One of the main characteristics of the so-called industry 4.0 is the application of technical solutions to retrieve data from industrial processes so that it can be analysed and processed afterwards. The goal of such exercise is to obtain relevant knowledge, that can be applied to improve these industrial processes and make them more efficient. For instance, by reducing the percentage of defects, or by detecting them in earlier stages of the production process, which typically reduces the economic costs of those defects.
In a typical Industry 4.0 scenario, most part of the data is generated by manufacturing devices acting as sensors and is dumped into a storage technology or tool. Then, there are several data analysis and processing tools that consume this data for different purposes. For instance, there are tools that perform data cleaning processes to remove useless cases, or to extract only the parts of data that really matters for a specific purpose. Other tools, such as dashboards, show the stored information in a more graphical and intuitive way, to facilitate some decision-making processes. Other important data consumers are big data analytics tools, that apply different algorithms to the data and allow, for example, to discover correlations and relationships among different variables of the analysed data.
In the case of the i4Q project, the i4Q Data Repository (i4QDR) is the solution covering all the data storage and retrieval requirements of the other solutions, which is presented in more detail in deliverable D3.8. Then, there are many other i4Q solutions that fall into the category of data analysis and processing tools mentioned, such as the i4Q Data Integration and Transformation Services (i4QDIT), the i4Q Services for Data Analytics (i4QDA), and i4Q Big Data Analytics Suite (i4QBDA), which are presented in deliverables D4.1, D4.2 and D4.3, respectively. These solutions take data previously stored in the i4QDR as input and produce new one that can be stored into it as well. Another source of data for the i4QDR is the i4Q Trusted Networks with Wireless and Wired Industrial Interfaces (i4QTN) solution (see deliverable D3.4), which oversees collecting data generated by actuators, sensors, and other IT/OT systems and give it as input for the i4QDR and the i4Q Analytics Dashboard (i4QAD) solution (described in deliverable D4.4). Figure 1 shows an overview of connection and interactions of the i4QDR, including other i4Q solutions. More specifically, elements in the box labelled as “Takes input from” are the ones requiring the storage of data into the i4QDR, whereas the ones located within the box labelled as “Gives input to” correspond to solutions retrieving data from the i4QDR.
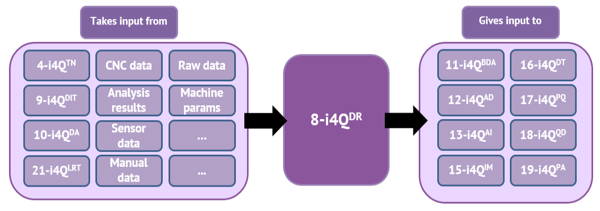
Figure 1. Connections and interactions of i4QDR#
Note that the i4QDR in some cases can be the final destination of the stored data, but in some other cases, the stored data will be provided as input for another solution that will further process it. This is well illustrated by the pipelines designed for the i4Q pilots. For instance, in Pilot 1 (see pipeline in Figure 2 ) data stored into the i4QDR will not be retrieved by any other solution, whereas in Pilot 3 (see pipeline in Figure 3) such data will be sent via the Message Broker to other solutions, and directly retrieved by the i4Q Prescriptive Analysis Tools (i4QPA) . As discussed above, storing, and retrieving data is a basic but crucial feature in an Industry 4.0 scenario. Therefore, the development of technical solutions providing that functionality, such as the i4QDR, must be addressed very carefully so that this feature is provided in the most appropriate way for each different component that interacts with it.
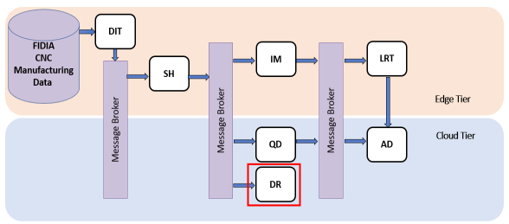
Figure 2. Pipeline of Pilot 1 (FIDIA)#
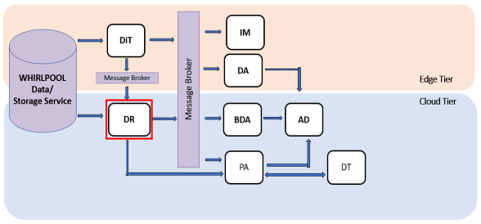
Figure 3. Pipeline of Pilot 3 (Whirlpool)#
Indeed, the interaction with other solutions is the main challenge for the development of the i4QDR. In this sense, some complexity arises just due to the number of different solutions interacting with the i4QDR. However, the highest degree of complexity is due to the fact that solutions retrieving or storing data from or into the i4QDR may need different functionalities from it, and, specially, have different technical requirements. For instance, some solutions may only need to store data, whereas other may need importing/exporting data from/to other data sources. Moreover, some solutions may require an SQL-style relational database, while others may require storing files.
This document provides the final version of the i4Q Data Repository Guidelines solution (i4QDRG), a guide devoted to the building of Data Repositories for Industry 4.0, which also tackles the estimation of storage capabilities and the building of technological systems that provide easy ways to access industry data and to communicate with industrial platform components and microservice applications. More specifically, this document focuses on the challenges that may arise during the development of a data repository, and some recommendations to address them.
The recommendations gathered in this document have guided the development of the i4QDR so far, up to M24. Therefore, this solution will be used as an example to illustrate some of the concepts and recommendations explained in this document.
2. Guideline on how to tackle data repositories for Industry 4.0#
Data repositories may be thought of as low-complex technical solutions, since they provide a basic functionality, namely the storage and retrieval of data. However, its development is quite challenging since, as explained in Section 1, they usually interact with many other components with different purposes. Consequently, in this context, the requirements of a data repository, especially the technical, are quite heterogenous, since the ones for a given component can be quite different from the ones for another component.
In this sense, a good example is the type of storage technology, which will vary depending on the type of data to be stored. For instance, SQL-based technologies are the suitable ones for structured and relational data, whereas NoSQL storage technologies are more appropriate for data whose structure may change over the time. However, it could also be the case that two components have contradictory requirements. For instance, some components running on premises with constrained resources will require light mechanisms to store just a few bytes of data, whereas other components may require more complex and powerful mechanisms to store large amounts of data.
Therefore, the development of data repositories in that context requires a balance between two opposite concepts. On the one hand, data repositories need to have a flexible design, so that they can fulfil heterogenous requirements coming from different dependent solutions. In the other hand, to reduce the complexity of the development, and the maintenance of the data repository once it is deployed, it is necessary to provide the required functionality in the most centralised fashion possible, by extracting as many common functionalities as possible and implement them in the most harmonised possible way. For instance, a data repository should try to offer only one interface to receive data from other solutions to store it, independently of the type of data. In this way, there is only one implementation for that feature, instead of one per storage technology.
The first step to address these challenges when developing a data repository is to identify which components interact with it, either to provide data that needs to be stored, or to retrieve data that has previously been stored. Then, for each solution interacting with the data repository, it is necessary to gather the specific needs regarding several aspects, such as:
The functionality required (e.g., only CRUD, or something else).
The volume of data.
Possible performance constraints, such as the expected number of read or write operations per second.
The operation mode. For instance, whether the data will be provided in an interactive mode, or in batch, and if will be done on-demand or as a scheduled task.
The need of replicated instances of the data repository.
The type of communications and expected interfaces and data formats.
Who and what components are authorised to access the data repository.
This information must be carefully analysed to make the decisions that will define the main aspects of the data repository’s design, namely:
The most appropriate tools and technologies for the type of data that will be managed.
The architecture of the data repository, which must be flexible to accommodate different requirements but, at the same time, should try to fulfil them in a centralised fashion whenever possible, as mentioned above.
The necessary storage configuration options considering the functional requirements and technical details such as the amount of data that will be handled, and the computing resources that will be available once the data repository is deployed.
For making these decisions it might be helpful to categorise needs and functionalities into those that are specific only to few solutions (or only one) and those that are common to several of them. Addressing the first group of needs might require using concrete tools. However, whenever possible, one should try to use tools that can work for other cases, too. Common needs and functionalities should be addressed in the most general and harmonised way. For instance, using the same technology or tool, whenever possible.
At the implementation level, the most important strategy is to simplify and reduce the complexity of the developments. This can be achieved, for instance, by providing only one implementation of a common functionality, independently of the solution requiring it. This can be the case, for instance, of access control. If the implementation differs depending on the solution the data repository is interacting with, it is recommended to analyse whether there are some sub-functionalities that can be implemented in the same way. For instance, if a solution needs to store data in a relational database, and another one needs to store a file in an object storage tool, the concrete mechanism to do so will be different in both cases. However, as mentioned above, the data repository can offer a common interface to receive the data to be stored, and then run the corresponding storage mechanism.
When different implementations for the same feature are necessary, the recommendation is to follow a similar structure and style to facilitate the identification of the functionality that is being implemented and the update of the code if changes are necessary in the future. An example of this is using similar class or method names.
Finally, another way to simplify and decrease the complexity of developments consists of reducing the number of dependencies and using tools and libraries that do not have too specific requirements. For instance, Docker is compatible with most common operating systems. Furthermore, Docker containers allow to abstract the (virtual) execution of a tool from the operating system (OS) in which Docker is running. This means that a tool running inside a Docker container executed on a Windows OS behaves exactly the same as when the tool is running in a Docker container executed on a Linux OS, assuming both containers have the same configuration.
3. Design specifications of the i4Q Data Repository#
This section describes how the design of the i4QDR and the definition of the strategy for its development have been approached so far, following the recommendations and guidelines provided in Section 2 to address the challenges and requirements arising when developing data repositories for Industry 4.0. Further details on the implementation of the i4QDR will be explained in deliverable “D3.16- i4Q Data Repository v2” (due on M24).
Regarding the interactions of the i4QDR with other components, the i4Q project includes a number of pilots and solutions that manage data one way or another and thus need mechanisms to handle such data. More specifically, the i4QDR, takes as input data from other i4Q solutions as well as raw data from other industrial components (e.g. CNC data or data gathered from sensors), and even data manually provided by a human user. Furthermore, the i4QDR provides data to other i4Q solutions, such as the i4QBDA, the i4QIM, the i4QPQ, etc. As explained in Section 2, Figure 1 gathers the interaction and connections of the i4QDR with other components and solutions. Further information on this topic can be found in deliverable “D1.9 –Requirements Analysis and Functional Specification v2” (Section 4.8).
With respect to the features and functionalities that the i4QDR is required to provide, the main needs common to all pilots and solutions are basic functionalities like storing data and retrieving the stored data. However, there are some additional generic requirements which are quite common in any storage technology, including:
Data persistence: the data is saved to a persistent storage and remains intact until it is altered or deleted on purpose.
Availability: the data is available to any of its legitimate users.
Privacy: the data is protected against unauthorized access.
Security: the data is protected against software and hardware failures.
Efficiency: with a proper use of the available resources.
Moreover, each pilot and solution have specific needs that involve several factors. One of the most important criteria is the type of the data to be stored, either relational, document-based, graph-oriented, blob-based, file-based, etc. This criterion on its turn affects other criteria. For instance, the use of enormous blobs or files may make a significant impact on the performance numbers. On the other hand, the same solution may have different needs depending on which pilot it is used. Thus, the i4QDR must be able to offer its services to its clients, under a wide range of needs, scenarios, and settings.
As a second step, needs related to the interoperability of the data have been identified. For instance, a pilot or solution generates data with different structures and/or syntax (e. g. relational and document-based data) or data that, for some reason, has to be handled by different storage tools. Another example may be the case of a solution that handles different sets of data and each one has different needs (formats, syntax, access patterns, performance requirements, etc.) and needs to use them in a unified way.
The i4QDR includes some off-the-shelf open-source tools. The selection of the current tools has been performed according to the needs of both the pilot and solution partners of the project. The procedure followed to produce such selection includes the following steps.
Prepare a questionnaire to ask about the needs a pilot or solution has regarding the i4QDR.
Receive the answers of the questionnaire and summarize them.
Identify which tools are specifically required by the partners.
Identify other tools that can satisfy the requirements and needs of the partners.
The questionnaire is a Microsoft Excel document available in a private repository2 (see Appendix I for further details). As shown in Figure 4, which provides an overview of such document, it includes a page for each pilot and solution partner. These pages contain a set of questions to be answered by each partner. The questions include these issues:
The types of storage mechanism needed by the pilot or solution (relational, structured, JSON-based, key-value-oriented, etc.).
Any information available so far regarding the volume of the data to be handled (for instance, in orders of magnitude).
The type of interaction that may be expected (interactive, batch, stream-oriented, etc.).
The type of communication interfaces that may be used (HTTP, HTTPS, TCP, etc.).
Any other requirement related to communication.
Any requirement or need related to data replication.
Any requirement regarding data privacy and security (access control, anonymization, etc.) that may apply.
Any specific deployment needs if any (on bare machines, Docker, Kubernetes, etc. and also on-premises vs cloud).
Any requirement or need regarding the performance.
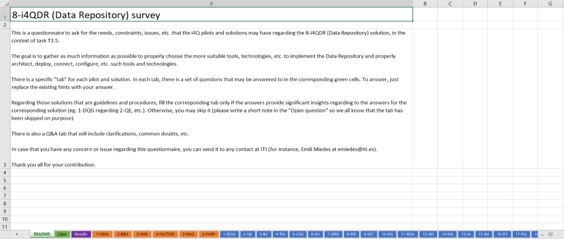
Figure 4. Overview of questionnaire to gather needs to be covered by the i4QDR#
After analysing the survey’s answers and carefully evaluating the needs of the partners, the following tools were selected:
Cassandra, a wide-column NoSQL distributed database server, appropriate for managing massive amounts of data.
MinIO, which offers a high-performance, S3 compatible object storage. It is used to store files and is compatible with any public cloud.
MongoDB, a JSON document-oriented database server.
MySQL, a SQL relational database server, very similar to MariaDB.
Neo4J, a graph database server that allows storing data relationships.
Redis, an in-memory data structure store, used as a distributed, in-memory key–value database, cache, and message broker, with optional durability.
In addition, the following tools have been included later, to satisfy additional needs and requirements brought out by some partners:
MariaDB, a SQL relational database server.
PostgreSQL, a SQL relational database server.
TimeScaleDB, a time-series SQL database which is an extension of PostgreSQL.
Note that both MySQL and PostgreSQL offer similar features, in the sense that they are SQL relational databases. However, it is not possible to use only one of them or replace them by MySQL to have only one tool for relational data storage because they were especially requested by some pilots to facilitate the integration with other technological systems.
Moreover, according to the needs of the pilot and solution partners, it has been decided to offer a variety of configurations or scenarios of each tool. These scenarios can be seen as different ways of deploying the tools to meet some requirements related to aspects such as performance or security. Generally speaking, for each tool, the following scenarios are considered:
A first basic single server (SS) scenario, which offers the tool in its most basic version. It leverages a single instance of the tool, ready to be used. It is worth noting that such single instances do not consider any security issue beyond its default configuration. Thus, an “SS” scenario is only recommended for the development tasks of a pilot or solution.
A single server with TLS security (SS+Sec) scenario, that offers the tool with a security configuration based on the use of TLS (with x509 certificates). This scenario is suitable for production settings in which a single instance of the tool suffices to provide a secure and stable service.
A high availability (HA) scenario, which offers the tool in a high availability mode. This typically involves defining some cluster or replica set environment, composed by a number of instances of the tool that work in a cooperative mode (for instance, a cluster of replicas of a database server). Again, these instances do not offer any security mechanism beyond those that are offered by default and are, thus, only recommended for development purposes.
Finally, a high availability with TLS security (HA+Sec) scenario, which extends the “HA” scenario with a security configuration based on the use of TLS. This is the recommend option to offer a secure, fault-tolerant, highly available service.
For each scenario, software artifacts are provided, including configuration files, Docker Compose orchestration files, and shell-scripts for Bash. Moreover, additional common configuration files and shell scripts are provided. The purpose of such artifacts is to deploy the selected storage tools according to the features of one of the four scenarios described above. Deliverable “D3.8 - i4Q Data Repository” (section 3.1 “Current implementation”) provides additional details about these artifacts. Moreover, it provides a summary about the status of the development of the scenarios of each tool.
Furthermore, the i4QDR includes another tool, Trino , which is a highly parallel and distributed ANSI SQL-compliant open-source query engine. These features enable a very efficient performance, even in the case of many simultaneous queries. Trino offers a relational-like view of a number of data storage tools including Cassandra, MariaDB, MongoDB, MySQL, PostgreSQL, Redis and others.
From an architectural perspective, Trino will be deployed as a layer on top of the different artifacts mentioned above, as illustrated in Figure 5. Note that there two storage technologies that do not appear below the Trino layer. On the one hand, there is Neo4J, as this storage tool is not currently supported by Trino. On the other hand, there is TimeScaleDB, a storage technology that has been included during M24 to cover a possible requirement for the generic pilot defined in T6.7. The list of Trino connectors does not include this technology. However, the plan is to check whether the connector for PostgreSQL could be used. Therefore, in these two cases, access to the storage tool will not be performed via Trino and, instead, it may require a direct connection or a dedicated access mechanism.
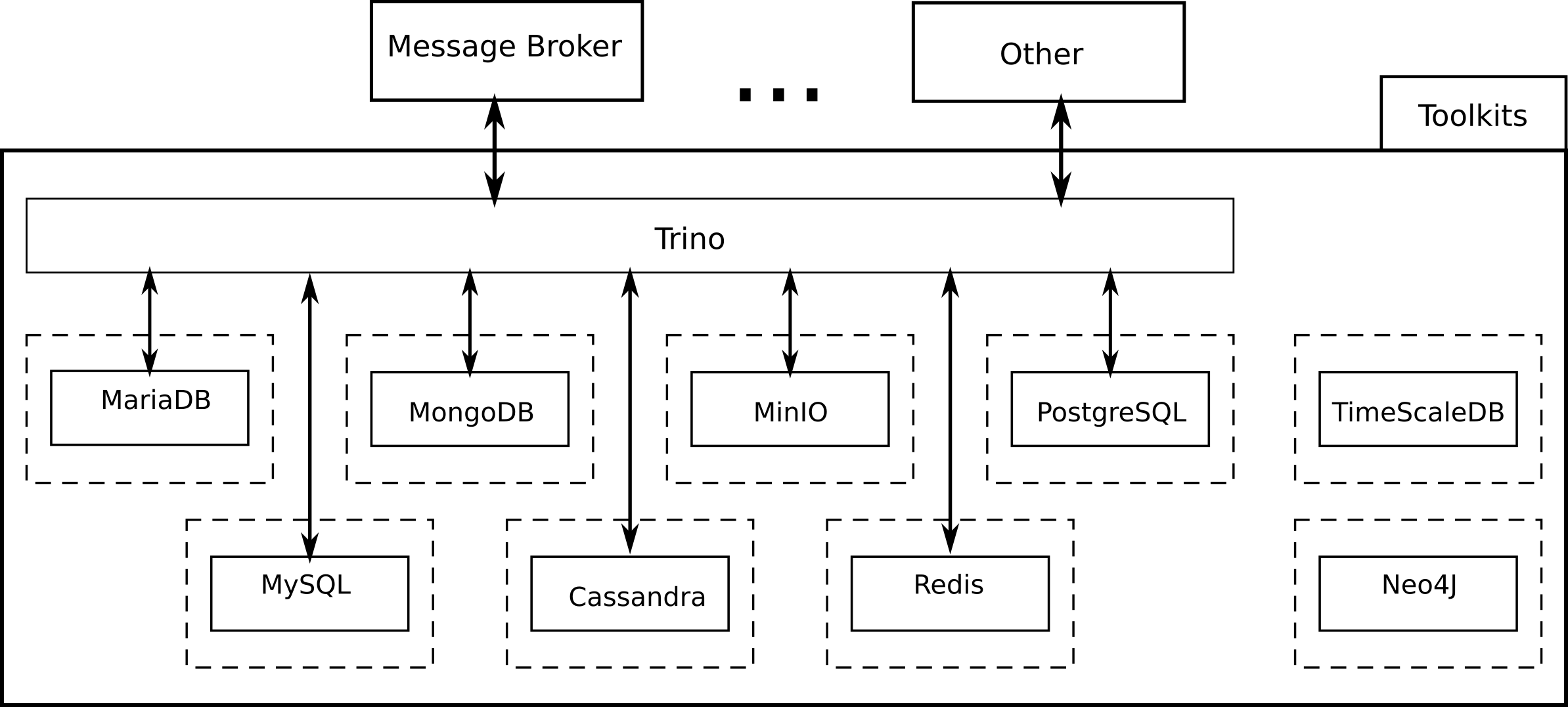
Figure 5. Architectural overview of i4QDR#
In the context of the i4QDR, besides its efficient performance, the most important benefits of using Trino are related to interoperability aspects. Firstly, it enhances interoperability at an internal level. In this regard, Trino adds a level of abstraction that allows the pilots and solutions to have a relational SQL-based view of different data storage tools, no matter what type of data they handle. This also allows to build federated views of data that is managed by a heterogeneous set of tools, which in turns allows to build more complex and interoperable software components.
Secondly, Trino also enhances the interoperability of the i4QDR at an external level since it facilitates its interaction with other i4Q solutions. More specifically, Trino allows the i4QDR to offer a common communication interface for all the selected storage tools. For instance, Trino offers a REST API which will allow the interaction of the i4QDR with other solutions by means of the HTTP protocol.
4. Communication with Data Repositories#
Just like for any software component, an important feature of data repositories is the communication and interaction with other software components, as mentioned in Section 1. This action typically involves the exchange of data among the two parties. In the specific case of data repositories, such a communication usually takes the form of a solution willing to store some data, or to retrieve it.
There are several approaches to the implementation of the communication of data repositories with other software components. One of the possibilities is to develop a general-purpose backend application offering a REST API to other components. In this approach, communications with the data repository are performed only at an internal level between the backend application and the data repository. Note that in this case external software components are not allowed to communicate directly with the data repository. Instead, they send HTTP requests to the endpoints defined in the REST API to get data from the repository, or store new data into it, or to update some fields of data already stored in the repository.
The approach of implementing REST APIs to allow interaction among different services is quite common in web programming. However, it might not be the most efficient one in the case of data repositories. Especially, when huge amounts of data are involved, and/or when the need to exchange data is very frequent, as it happens in industrial scenarios, where machines, sensors and other devices often generate data in a continuous way. In this type of scenarios, it is more appropriate to use tools specifically designed and implemented for these requirements. One of the most well-known tools used for this use cases is Apache Kafka.
Apache Kafka is an open-source platform for event streaming capable of handling huge amounts of messages in real-time. It is used in all sorts of real-time data streaming applications as it is highly scalable while providing high data throughput with low latency.
As explained in [1] a deployment of Kafka consists of server and client applications that communicate via a high-performance TCP network protocol. Clients read, write, and process streams of messages (also called record or events in the documentation), whereas servers oversee the management and persistence of the messages exchanged among clients. There are two types of clients: producers, the ones that publish (write) messages to Kafka, and consumers, which subscribe to (read and process) these messages.
The communication in Kafka is conducted using Kafka topics. A topic is an abstraction that acts as an intermediary between producers and clients. More specifically, producers publish messages in a certain topic and clients can later consume these messages via subscribing to that specific topic. The data format of the messages can be either JSON or Avro which is a more efficient and compact way of exchanging messages, with a data model similar to JSON.
In this project the approach followed by the i4Q Data Repository (i4QDR) is to support different ways of communication, so that other i4Q solutions or external software components can use the one that suits best their needs. The supported approaches are as follows:
First, it is possible interact directly with the server application that can be deployed for each one of the storage technologies. Such communication can be made by means of scripts or programs, possibly using of libraries provided by third parties for that purpose, which depend on the chosen programming language.
Secondly, for some storage technologies, the i4QDR also deploys an instance of a specific graphical client application. This is the case, for instance, of MinIO or MongoDB scenarios, when the i4QDR deploys an instance of MiniO console (see Figure 6), and Mongo Express (see Figure 7), respectively. These applications allow a more user-friendly mechanism to interact with the deployed database, such as browsing or querying the stored data.
However, they are not intended for an intensive use, such as for inserting big amounts of new data.
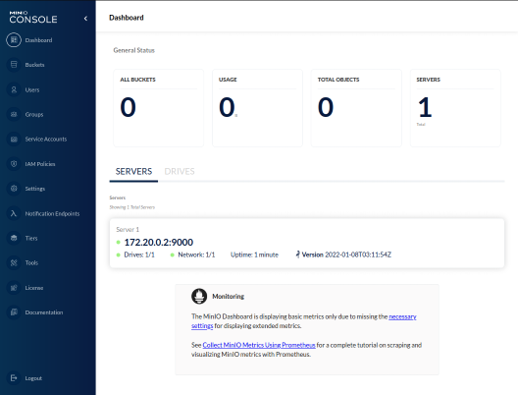
Figure 6. MinIO Console deployed by the i4QDR for any MinIO scenario.#
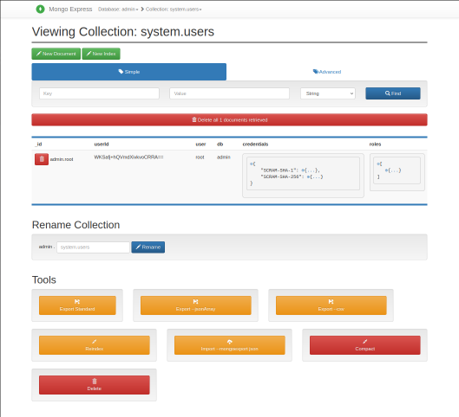
Figure 7. Mongo Express instance deployed by the i4QDR for any MongoDB scenario.#
Since the i4QDR deploys an instance of Trino, the third possibility is to interact with the i4QDR by using the mechanisms provided by Trino for that purpose. More specifically, it is possible to send queries to Trino and receive results, or otherwise interact with Trino and the connected data sources by means of the official clients provided at Trino’s official website (check https://trino.io/docs/current/client.html), or by some others developed by the community (see https://trino.io/resources.html) for platforms such as Python, and these can in turn be used to connect applications using these platforms. Furthermore, Trino provides a client REST API that allows submitting queries by making HTTP requests. However, the preferred method to interact with Trino is using the existing clients above mentioned.
5. Communication with Data Repositories#
This web documentation provides an overview of the importance of data repositories in Industry 4.0 contexts. In Section 1 this explanation was illustrated with the i4QDR, the technical solution that will cover the data management requirements of any solution or pilot in the context of the i4Q project.
Moreover, these guidelines gathers the main problems and challenges arising when developing such data repositories. In this regard, a non-exhaustive list of recommendations addressing these problems and challenges has been proposed with the purpose of serving as a guideline for the development of data repositories. Indeed, Section 3, as an illustrative example, describes in detail how these recommendations have been applied in practice during the design of the i4QDR solution, and the definition of its development strategy.
Communication with data repositories from/to other software solutions is an important issue tackled in this document. In this regard, Section 4 provided an overview of the most common approaches to implement this issue, and briefly explains how this has been done in the case of the i4QDR solution.
In order to provide the information gathered in this deliverable in a more user-friendly fashion, a web application has been implemented to show its most relevant content in the style of standard web documentation, as explained in Section 5.
6. References#
[1] «Apache Kafka official website» [Online]. Available: https://kafka.apache.org. [Accessed: November 2022].